BytebaseのようにSQLだけでなく任意のワンショットのコマンドの実行をAtlantisのワークフローに乗せられるのではないか…ということを思いついたので検証してみた。
まずワンショットのコマンドのterraform providerを作成。
resource "oneshot_run" "hello" { command = "echo 'hello, oneshot'" plan_command = "echo \"hello, oneshot (plan=$ONESHOT_PLAN)\"" }
terraform planでplan_commandで実行され、terraform applyでcommandが実行される(plan_commandはapply時には実行されない)。
plan_commandのログがplan-stdout.log plan-stderr.log に、commandのログが stdout.log stderr.log に出力される。
terraformなので、一度apply(実行)されたら二度目は実行されない。
Atlantisのワークフローの設定は以下の通り。
workflows: operation: plan: steps: - init - run: echo "[WARN] Plan command was not executed" > plan-stdout.log - run: touch plan-stderr.log - run: command: terraform${ATLANTIS_TERRAFORM_VERSION} plan -input=false -refresh -out $PLANFILE output: hide - run: cat plan-stdout.log - run: cat plan-stderr.log apply: steps: - run: echo "[WARN] Apply command was not executed" > stdout.log - run: touch stderr.log - run: command: terraform${ATLANTIS_TERRAFORM_VERSION} apply $PLANFILE output: hide - run: cat stdout.log - run: cat stderr.log
GitHubのコメントが冗長なのでテンプレートを上書き。
- プロジェクトごとのapply/delete/planコマンドのコメントを削除
<details>...</details>の折りたたみを削除
- plan_success_unwrapped.tmpl
{{ define "planSuccessUnwrapped" -}}
{{ if .EnableDiffMarkdownFormat }}{{ .DiffMarkdownFormattedTerraformOutput }}{{ else }}{{ .TerraformOutput }}{{ end }}
{{ if .PlanWasDeleted -}}
This plan was not saved because one or more projects failed and automerge requires all plans pass.
{{ end -}}
{{ template "mergedAgain" . -}}
{{ end -}}
- plan_success_wrapped.tmpl
{{ define "planSuccessWrapped" -}}
{{ if .EnableDiffMarkdownFormat }}{{ .DiffMarkdownFormattedTerraformOutput }}{{ else }}{{ .TerraformOutput }}{{ end }}
{{ if .PlanWasDeleted -}}
This plan was not saved because one or more projects failed and automerge requires all plans pass.
{{ end -}}
{{ .PlanSummary -}}
{{ template "mergedAgain" . -}}
{{ end -}}
任意のコマンドを実行するPRを作成してみる。
resource "oneshot_run" "any_command" { command = <<-EOT echo 'これはapplyに実行されるコマンドの出力だよ' EOT plan_command = <<-EOT echo -e "これはplanで実行されるコマンドの出力だよ\n(plan=$ONESHOT_PLAN)" EOT }
Atlantisでplan_commandが実行されて結果がコメントとして追記される。
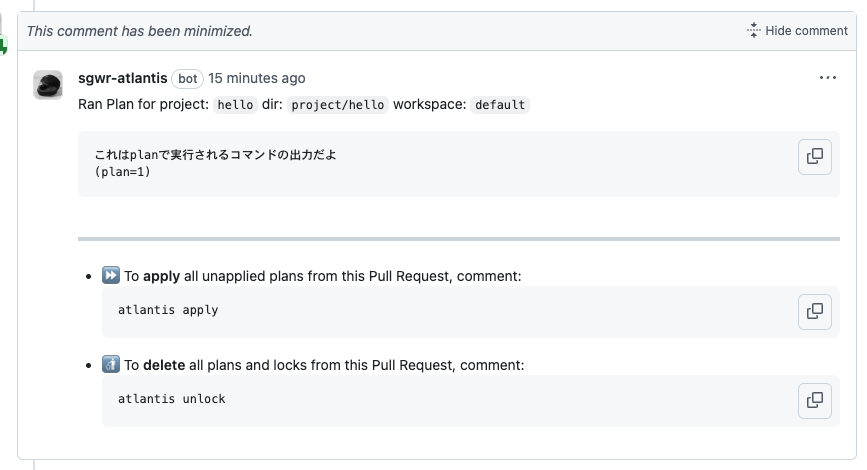
plan_commandを修正してpush。
diff --git a/project/hello/terraform.tf b/project/hello/terraform.tf index f1f2851..b88f327 100644 --- a/project/hello/terraform.tf +++ b/project/hello/terraform.tf @@ -27,6 +27,6 @@ resource "oneshot_run" "any_command" { echo 'これはapplyに実行されるコマンドの出力だよ' EOT plan_command = <<-EOT - echo -e "これはplanで実行されるコマンドの出力だよ\n(plan=$ONESHOT_PLAN)" + echo -e "これはplanで実行されるコマンドの出力だよ\n※修正したよ※\n(plan=$ONESHOT_PLAN)" EOT }
修正したコマンドが実行される。
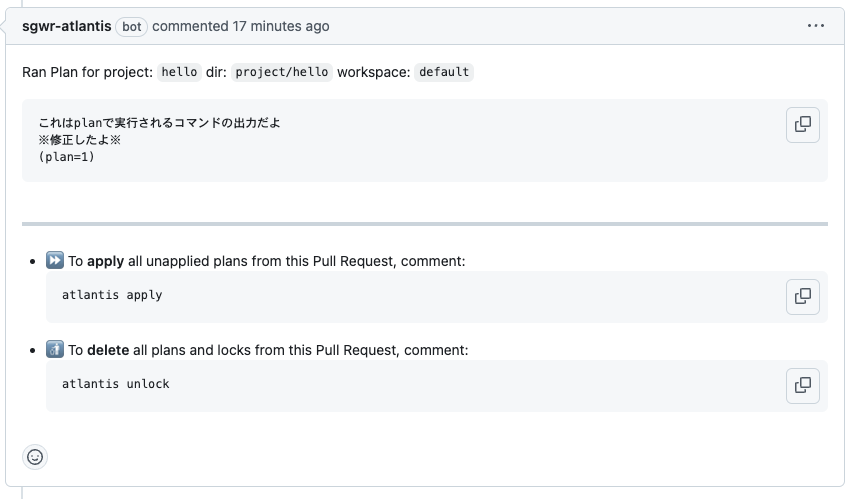
atlantis applyとコメントするとcommandが実行される。
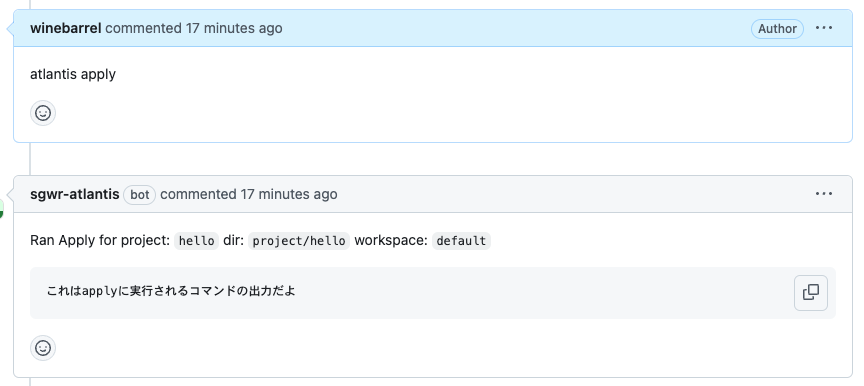
メモ
resource "example_thing" "example" { for_each = fileset("scripts", "**/main.sh") command = each.value plan_command = each.value }
# main.sh if [ "$ONESHOT_PLAN" = "1" ] ; then # (planの処理) else # (applyの処理) fi
- atlantis planで検証用のplan_commandが実行されるのは悪くない、ような気がする
- 任意のコマンドを実行できるのでセキュリティまわりが大変かも
- 入出力に秘匿情報がある場合はどうしたらよいか…
- plan/apply時にコマンドではなくterraform自体の出力を出す必要があるかも知れない