
最初に断っておくとこれは懺悔のエントリです。
- スライド: DynamoDBのまえにキャッシュおく奴
AWS Casual Talksでのグタグタな発表申し訳ありませんでした! (あと、マイク持っていただいた @takipone さん、ありがとうございます。AWS Advanced User Meetupをよろしくお願いします)
言い訳をさせていただくといくつかの業務と顎関節症でテンパっていたのです…。 痛み止めをがばがば飲んだのがあだとなりました。
Redy - DynamoDBのまえにキャッシュおく奴
さて、Redyの話です。
https://github.com/winebarrel/redy
経緯とか
以前、AWS Advanced User MeetupでさんざんDisったのですが*1、DynamoDBはスパイクが辛いです!動的にスループットをあげようとしてもCloudWatchの分解能が5分!
辛い…
さらに某社サービスのセッション管理に利用しようとしたところ、r/wそれぞれ10,000qpsで月々70万円近く…
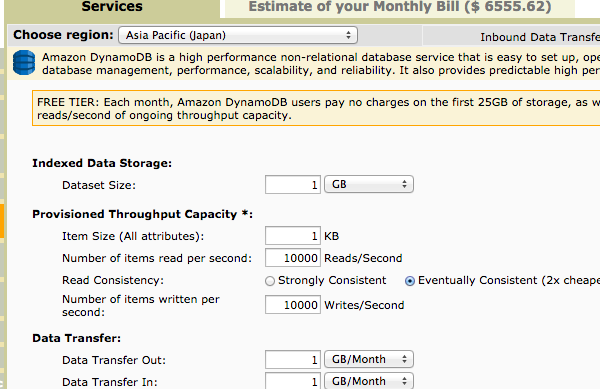
Redisだったら、m3.largeぐらいで捌けるのに…
じゃあRedisつかえって話なんですが、容量が100GBぐらいは超えそうでメモリを確保しようとするとそれも高い。 クラウドの世界はMoneyですねー…
そこでDynamoDBのまえにキャッシュおく奴を作ったわけですが、事情によりお蔵入りとなりました。
まあ、DynamoDBのまえにキャッシュおくとか謎ですよね…フルマネージドはどこ行ったのかと。
月日は流れ、AWS Casual TalksのLTをすることになり*2せっかくなので、個人のリポジトリに移して公開してみました。
アーキテクチャ


アーキテクチャはまんまシンプルで、DynamoDBのまえにRedisをおいてキャッシュさせて、fluentdを使って非同期にDynamoDBに書き込むようにしています。 fluentdからDynamoDBへの書き込みは拙作のfluent-plugin-dynamodb-altを使っています。
Redisはただのキャッシュなので、Redisが落ちたとしても…
 直接、DynamoDBに読み書きするので動作に支障はないです(当然、スループットは落ちます)。
直接、DynamoDBに読み書きするので動作に支障はないです(当然、スループットは落ちます)。
Redisはほんとただのキャッシュですね。memcachedの代わりです。memcachedを使っていないのはレプリケーションがあるからで、設定のsave ...をコメントアウトすれば、ただの高機能なmemcachedとして使えます。
インストール
rubygemsには登録してないので、gitから直接インストールしてください。
gem 'redy', :git => 'https://github.com/winebarrel/redy.git'
使い方
まず、Redyインスタンスを生成します。
redy = Redy.new( redis: {namespace: 'redy', host: 'redis'}, fluent: {tag: 'dynamodb.test', host: 'fluentd'}, dynamodb: {table_name: 'my_table', timestamp_key: 'timestamp', delete_key: 'delete'}, )
DynamoDBのテーブル定義例は以下の通り。*3
ap-northeast-1> show create table my_table; CREATE TABLE `my_table` ( `id` STRING HASH ) read=100 write=100
fluentdの設定は以下の通り。
<source>
type forward
</source>
<match dynamodb.**>
type dynamodb_alt
table_name my_table
timestamp_key timestamp
binary_keys data
delete_key delete
expected id NULL,timestamp LE ${timestamp}
conditional_operator OR
flush_interval 1s
concurrency 4
</match>
async: trueを指定して*4書き込みすると、普通に値が保存されます。
irb(main):006:0> redy.set("foo", 100, async: true) => 100 irb(main):007:0> redy.get("foo") => 100
Redisにキーが保存され、DynamoDBにもキーが保存されています。(MessagePackでシリアライズしています)
[ec2-user@redis ~]$ redis-cli redis 127.0.0.1:6379> get redy:foo "d"
ap-northeast-1> select all * from my_table; [ {"data":"ZA==","id":"foo","timestamp":1414817944199268} ] // 1 row in set (0.05 sec)
削除すると、Redis・DynamoDBから削除されます(Redisはネガティブキャッシュのため空文字になります)
irb(main):008:0> redy.delete("foo", async: true) => "OK" irb(main):009:0> redy.get("foo") => nil
redis 127.0.0.1:6379> get redy:foo ""
ap-northeast-1> select all * from my_table; [ ] // 0 row in set (1.23 sec)
これらの動作はRedisが落ちていても変わりません。
ベンチマーク
t2.microで簡単なRubyスクリプトを走らせてみたところ
ts = tg = td = nil bm do |x| ts = x.report('1,000 set:') { 1_000.times do |i| redy.set("foo#{i}", {'bar' => 100, 'zoo' => 'baz'}, async: true) end } tg = x.report('1,000 get:') { 1_000.times do |i| redy.get("foo#{i}") end } td = x.report('1,000 del:') { 1_000.times do |i| redy.delete("foo#{i}", async: true) end } sum = ts + tg + td avg = sum / 3 [sum, avg] end puts <<-EOS set: #{'%.3f' % ts.real} ms #{'%.2f' % (1000.0 / ts.real)} qps get: #{'%.3f' % tg.real} ms #{'%.2f' % (1000.0 / tg.real)} qps del: #{'%.3f' % td.real} ms #{'%.2f' % (1000.0 / td.real)} qps EOS
結果は以下の通り。
[ec2-user@client redy]$ ./test.rb
user system total real
1,000 set: 0.130000 0.020000 0.150000 ( 0.402171)
1,000 get: 0.090000 0.010000 0.100000 ( 0.360350)
1,000 del: 0.150000 0.000000 0.150000 ( 0.427252)
0.370000 0.030000 0.400000 ( 1.189773)
0.123333 0.010000 0.133333 ( 0.396591)
set: 0.402 ms 2486.51 qps
get: 0.360 ms 2775.08 qps
del: 0.427 ms 2340.54 qps
並列化すれば、もっとスループットをあげられると思います。 まあ、DynamoDBへの書き込みは遅延しているわけですが…
まとめ
10,000qps程度の読み書きでスパイクとお金に困っている方はRedyを利用してみるのもいいんじゃないでしょうか? 業務に突っ込もうとしていたので、テストはかなりまじめに書いています。
もし、なにかとち狂って業務に突っ込んだ方がいたら結果を教えていただきたいです。
蛇足
10,000qpsぐらいの環境でDynamoDB使っているよーって方がいたら、事例を詳細に教えてほしいですね。 特に¥とか$とか㊎とかを…